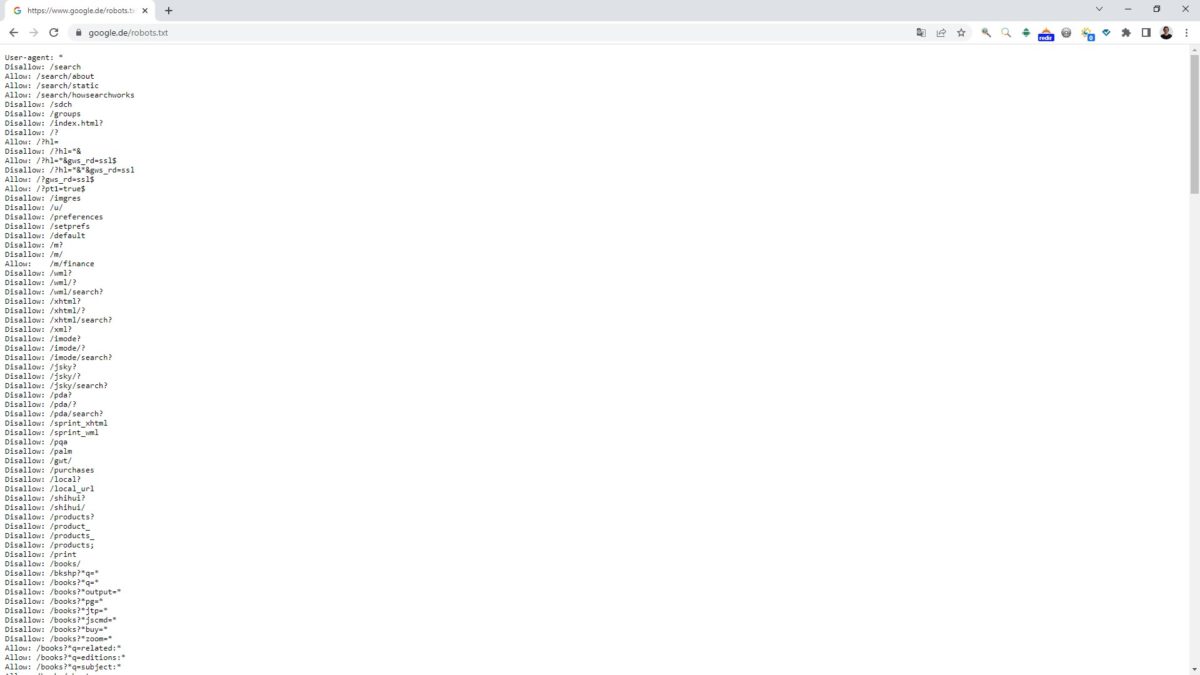
Über die robots.txt Datei kann das Crawling von Suchmaschinen gesteuert werden. Das bedeutet, dass Crawler darüber informiert werden, welche Inhalte einer Seite sie nicht abrufen dürfen. Dazu muss die robots.txt im sogenannten Root-Verzeichnis einer Domain abgelegt und folglich unter z.B. https://www.stephan-czysch.de/robots.txt abrufbar sein.
Die Crawler großer Suchmaschinen halten sich an die dort definierten Angaben. Über den sogenannten User-Agent können einzelne Crawler gezielt angesprochen werden. Dadurch ist es möglich, z.B. allen Crawlern mit Ausnahme des Googlebot das Crawling zu verbieten.
Warum eine per robots.txt blockierte Adresse in der Google-Suche erscheinen kann und dort aktuell mit dem Hinweis „Für diese Seite sind keine Informationen verfügbar. Weitere Informationen“ angezeigt wird, erklärt dieser Artikel.
Inhalt
Beispielhafter Aufbau einer robots.txt
Angenommen, dass für alle Suchmaschinen das Crawling des Ordners „keine-robots“ unterbunden werden soll, muss in der robots.txt folgende Regel definiert werden:
User-agent: *
Disallow: /keine-robots/
Mittels User-agent: * werden alle Crawler angewiesen, die folgenden Angaben zu befolgen. In diesem Fall ist das Crawling für das Verzeichnis „/keine-robots/“ ausgeschlossen.
Wichtig: Crawling-Verbot schützt nicht vor der Indexierung
Ein häufiger Trugschluss ist der Glaube, dass vom Crawling ausgeschlossene Dateien oder Verzeichnisse nicht von Suchmaschinen indexiert werden. Doch Crawling hat mit Indexierung erstmal wenig zu tun. Der für das Crawling ablaufende Prozess sieht wie folgt aus:
- Über einen Verweis findet eine Suchmaschine eine URL (Webadresse). Dadurch wird die Adresse (aber erstmal nicht deren Inhalt!) bekannt
- Per Abgleich mit der robots.txt wird ermittelt, um die Seite gecrawlt (also gelesen) werden darf.
- Wenn die Adresse für das Crawling freigegeben ist (also nicht per robots.txt unterbunden wird), wird deren Seiteninhalt erfasst. In diesem Zuge können die Indexierungsangaben (z.B. über Meta Robots) gefunden werden.
Liegt ein Crawling-Ausschluss für die Adresse vor (also steht ein Muster der URL in der robots.txt auf Disallow), dann kennt die Suchmaschine nicht den Seiteninhalt. Entsprechend weiß die Suchmaschine nicht, welche Inhalte auf der Seite zu finden sind. Das beeinhaltet auch die Robots Angaben, die womöglich ein „Noindex“, also die Nicht-Indexierung, an Suchmaschinen anweist. Entsprechend kann die Adresse von Suchmaschinen ohne weitere Informationen über den Inhalt indexiert und somit über Suchmaschinen gefunden werden.
In der Google-Suche tauchen per robots.txt blockierte Adresse mit dem Hinweis „Für diese Seite sind keine Informationen verfügbar. Weitere Informationen“ auf. Dieser anstelle der Meta Description angezeigte Text wird von Google von Zeit zu Zeit angepasst. So stand dort früher „Aufgrund der robots.txt dieser Website ist keine Beschreibung für dieses Ergebnis verfügbar.“.

Ältere Varianten für den anstelle der Meta Description angezeigten Text sind:

Der Seitentitel selbst entspricht dabei seltenst dem Titel, der auf der Seite definiert ist. Denn diesen kann die Suchmaschine durch die Crawling-Blockierung nicht einlesen. Der Seitentitel wird deshalb aus Ankertexten der Links zu dieser Seite gebildet.
Wenn Sie nicht möchten, dass eine Seite überhaupt über die Google-Suche gefunden werden kann, dann müssen Sie:
- Das Crawling dieser Adresse erlauben (ergo: Nicht per robots.txt blockieren)
- Und die Indexierung über Noindex verhindern
Warum sollte man die Suchmaschinen-Roboter steuern?
Gerade bei sehr großen Webportalen und Online-Shops ist eine gezielte Steuerung der Suchmaschinen-Robots unabdingbar. Die Crawler der reichweitenstärksten Suchmaschine in Deutschland, Google, haben pro Website/Domain nur ein bestimmtes Kontingent an freien Ressourcen für das Erfassen der Inhalte („Crawlingbudget“). Der Umfang der Ressourcen steigt zwar u.a. mit der Größe des Portals, jedoch sind sie nicht unendlich. Damit alle für Sie wichtigen Inhalte immer im Bestfall schnellstmöglich und aktuell gecrawled werden können, ist die Einrichtung von gewissen Crawling-Regeln nötig.
Übrigens: Über die robots.txt sollte auch eine eventuell verfügbare sitemap.xml-Datei referenziert werden. Dieser Verweis sieht dabei wie folgt aus „Sitemap: https://www.stephan-czysch.de/sitemap.xml“
So testen Sie Ihre robots.txt
Die in der robots.txt definierbaren Regeln sind mitunter sehr komplex und können zu einem unerwarteten Crawling-Verhalten führen. Innerhalb der Google Search Console (Tipp: Alles über Google Search Console im O’Reilly Fachbuch) haben Sie die Möglichkeit, die robots.txt-Datei zu überprüfen.
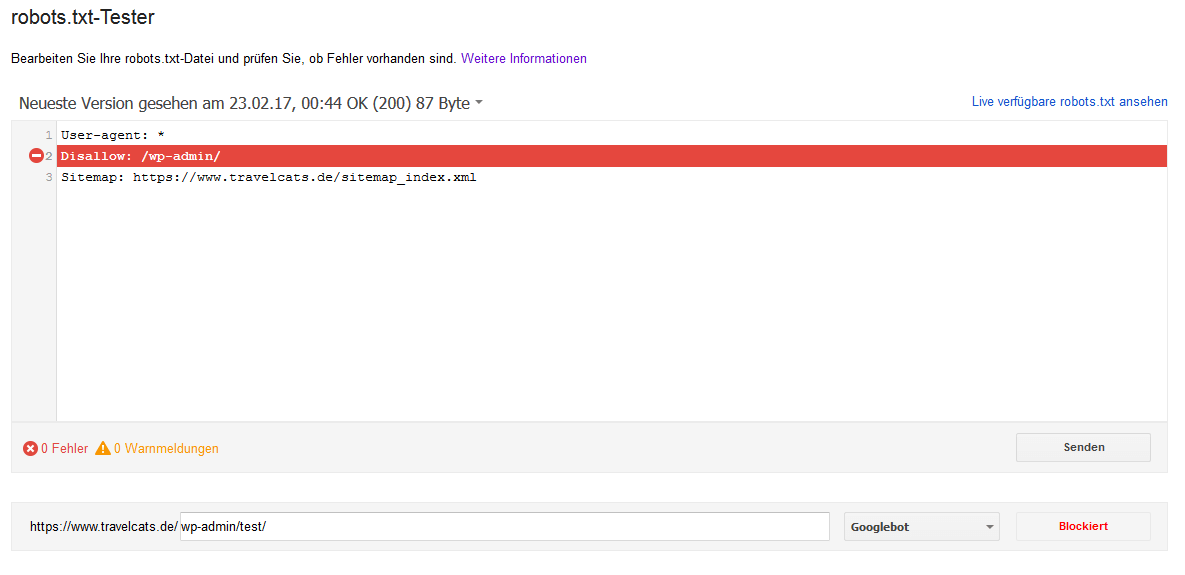
Diese Option finden Sie unter „Status“, „Blockierte URLs“ – es empfiehlt sich, Änderungen an der robots.txt vorab über dieses Tool zu testen und erst anschließend die Änderungen auf den Webserver zu übertragen. Über „Senden“ können Sie Google über eine Veränderung an der robots.txt informieren.


